
[Paper Review] SELFCHECKGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models (EMNLP 2023)
Published:
Black-Box LLM으로 Hallucination 감지
Abstract
LLM은 hallucination과 같은 사실이 아닌 정보들을 생성하는 경향이 있다. 이러한 hallucination을 측정하기 위해 기존에는 출력 확률 분포 혹은 외부 데이터 베이스을 사용하여 fact-checking을 하였다. 이러한 접근법들은 ChatGPT와 같은 closed-LLM에서는 사용이 불가능하거나, 외부의 복잡한 모듈을 사용한다는 문제점이 있다. 따라서, 해당 논문에서는 zero-resource 환경에서 black-box 모델의 샘플링 기반 fact-checking 방법론인 SelfCheckGPT를 제안한다. LLM이 주어진 문맥에 대한 정보가 있다면 샘플링된 응답들이 비슷하고 일관될 것이며 만약 사실과 다른 정보가 있다면 다른 응답들과 모순될 것이라는 가정에 기반한다.
Introduction
GPT-3와 PaLM과 같은 LLM들은 사용자의 프롬프트에 대해 자연스럽고 사실적인 응답들을 생성한다. 하지만 LLM이 종종 잘못된 정보들을 생성함에 따라, 이를 감지할 수 있는 방법에 대한 연구의 필요성이 논의되었다. 이러한 hallucination을 감지하기 위해 기존의 연구에서는 intrinsic uncertainty metric을 활용하였다. 하지만 uncertainty metric은 token-level probability를 활용하여 토큰 확률 혹은 엔트로피를 계산해야 하는데, GPT의 경우 접근이 불가능하다. 외부 데이터베이스를 활용하는 방법의 경우 database에 우리가 필요로 하는 정보가 포함되어 있을 경우에만 사용이 가능하다. 따라서, 해당 논문에서는 샘플링 기반의 fact-checking 방법론을 제안한다. LLM을 통해 여러 응답을 생성한 뒤 각 응답들 간의 consistency를 비교함으로써, black-box 환경에서도 사용이 가능하다.
Grey-Box Factuality Assessment
LLM의 output distribution에 접근할 수 있을 때 factuality를 측정하는 방법이다. 생성된 응답들의 factuality를 정의하기 위해 LLM의 pre-training을 고려한다. Pre-training 과정에서 대규모 텍스트 데이터를 통해 모델은 next-word prediction으로 학습을 하게 되는데, 해당 과정에서 모델은 언어에 대한 강한 이해를 얻게 된다. 예를 들어, “Lionel Messi is a _‘라는 프롬프트가 주어졌을 때 “Lionel Messi”는 유명인이기에 pre-training 과정에서 “footballer”가 높은 확률을 가질 것이다. 반면에 입력이 “John Smith is a _” 주어진다면 모델은 어떤 토큰을 생성할 지 확실하지 않기 때문에 플랫한 확률 분포를 가질 것이다. 이를 통해, uncertainty metric과 factuality의 관계가 있다는 것을 알 수 있다. 따라서, 해당 논문에서는 사실적인 문장들은 높은 likelihood와 낮은 엔트로피를 가지며 hallucination은 플랫한 확률 분포와 높은 불확실성을 가진다고 주장한다.
$i$-th 문장의 $j$-th 토큰의 토큰 확률 다음과 같이 2가지 방법으로 구할 수 있다. $Max(-logp)$ 는 문장의 가장 덜 likely한 토큰의 likelihood를 측정함으로써 문장의 likelihood를 측정한다.
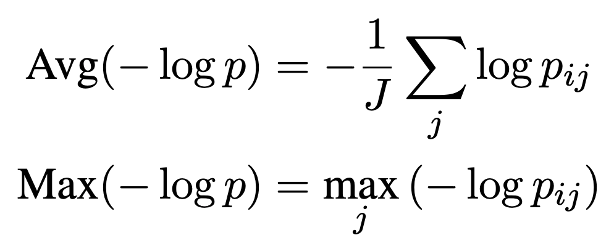
엔트로피는 다음과 같이 계산할 수 있다. $p_{ij}(w)$ 는 $i$-th 문장의 $j$-th 토큰에서 단어 $w$가 생성될 확률이며 $W$는 전체 가능한 단어를 의미한다. 위의 확률 기반의 metric과 유사하게 entropy기반의 metric도 2가지로 측정한다.
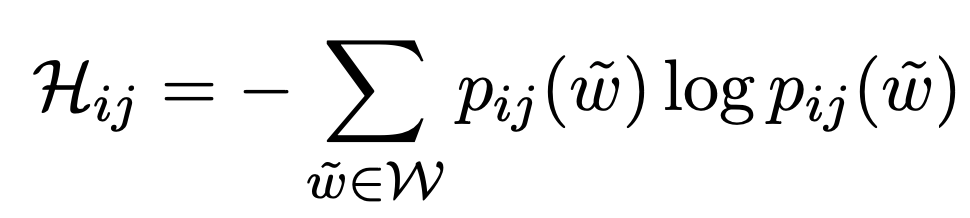
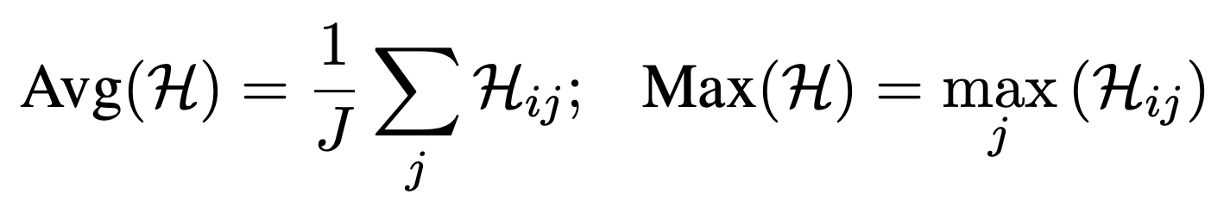
Black-Box Factuality Assessment
ChatGPT와 같은 API call을 통해 호출해야 하는 모델들의 경우 token-level probabilities에 접근하지 못하기에 Grey-box 방법들은 한계가 있다. 따라서, 해당 논문에서는 black-box 방법론들을 제안한다.
Proxy LLMs
간단하게 grey-box처럼 사용하는 방법은 별개의 오픈소스 LLM을 통해 black-box LLM의 output token-level probability를 근사하는 proxy LLM을 사용하는 것이다.
SelfCheckGPT
해당 논문에서는 동일 프롬프트로부터 생성된 여러 응답들을 비교하는 SelfCheckGPT을 제안한다. $R$은 사용자의 쿼리로부터 얻은 LLM 응답이며, ${S^{1}, S^{2}, …, S^{n}, …, S^{N}}$은 같은 쿼리로부터 얻은 stochastic하게 얻은 sample이다. $i$-th 문장의 hallucination 점수 $S(i) \in [0.0, 1.0]$는 0.0일 때 유효한 정보, 1.0일 때 hallucination으로 정의한다.
w/ BERTScore
$B$가 문장 간의 BERTScore라 할 때, response $R$의 i-th sentence문장과 $N$개의 sample의 문장 간의 BERTScore를 측정하여 각 샘플에 대해 가장 큰 BERTScore를 측정한다. 해당 방법의 경우 정보가 사실이더라도 다른 sample에 없다면 hallucination으로 측정될 수 있다.
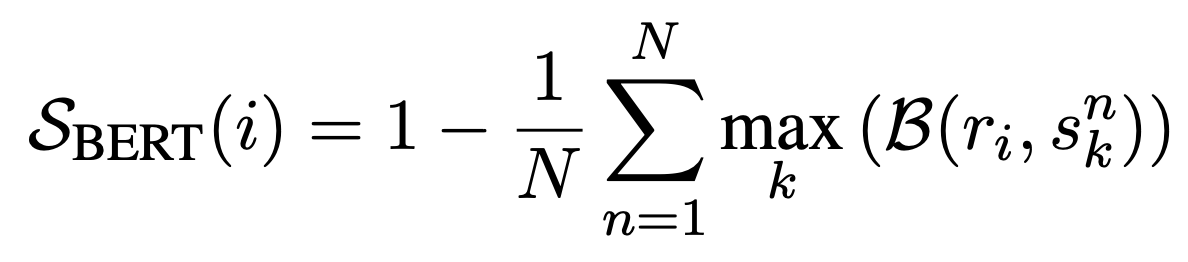
w/ Question Answering
해당 방법은 multiple-choice question answering generation (MQAG)를 활용한 방법이다. MQAG를 통해 response에서 multiple-choice 질문들을 생성한 후에, 별개의 answering system이 sampled responses의 조건 하에 답변한다. 만약 질문들이 일관된 정보를 가진다면 answering system이 비슷한 정답을 낼 것이라 가정한다.
MQAG는 question을 생성하는 $G$와 question ansewring $A$ 의 two stages로 구성된다. 먼저, Response $R$의 각 문장 $r_{i}$에서 질문 $q$와 옵션 $o$을 추출한다.
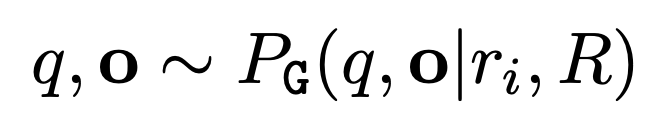
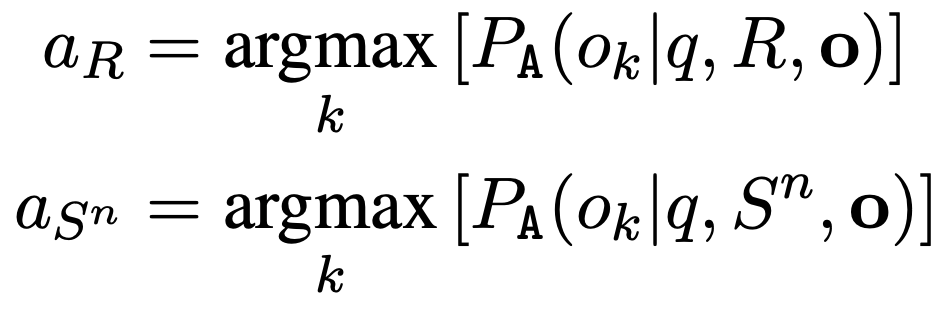
그 후에 각 답변 $a_{R}$이 $a_{S^{n}}$과 같은지 비교한다. 답변이 매칭되는 개수 $N_{m}$와 답변이 매칭되지 않는 개수 $N_{n}$을 아래와 같은 식으로 계산한다.
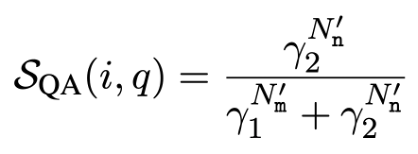
따라서, 최종 점수는 아래와 같다.
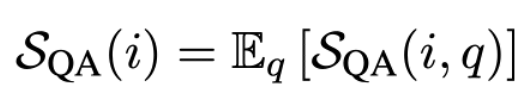
w/ n-gram
LLM을 통해 생성한 여러 sample들을 통해 새로운 language model을 학습하는 방법도 있다. 만약 N이 충분히 크다면 LLM에 수렴할 수 있기에, LLM의 토큰 확률을 새로운 language model로 활용할 수 있다. 해당 실험에서는 cost의 한계로 인해 제한된 N개를 사용한다. 결과적으로 N개의 LLM sample과 response $R$로(smoothing) 간단한 n-gram 모델을 학습한다. 이전과 마찬가지로 두 가지의 variation을 사용한다.
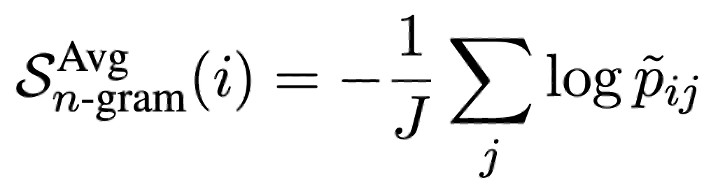
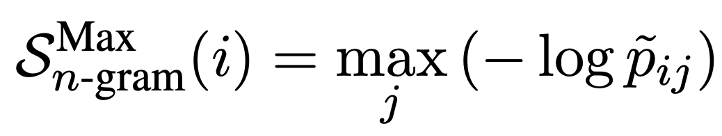
w/ NLI
Summarization과 같은 다른 task에서 faithfulness를 측정할 때 많이 사용하는 NLI를 통해 측정한다. NLI 분류 모델의 입력으로 premise와 hypothesis를 넣어서 사용하기에 해당 모델에는 sampled passage $S^{n}$에 평가하고자 하는 문장 $r_{i}$를 결합하여 입력으로 사용한다. 레이블은 ‘entailment’와 ‘contradiction’만을 사용하며, 각 레이블에 해당하는 logit을 계산한다. ‘neutral’에 해당하는 레이블을 무시하고 probability를 [0.0, 1.0]으로 제한하기 위해 다음과 같이 계산한다.
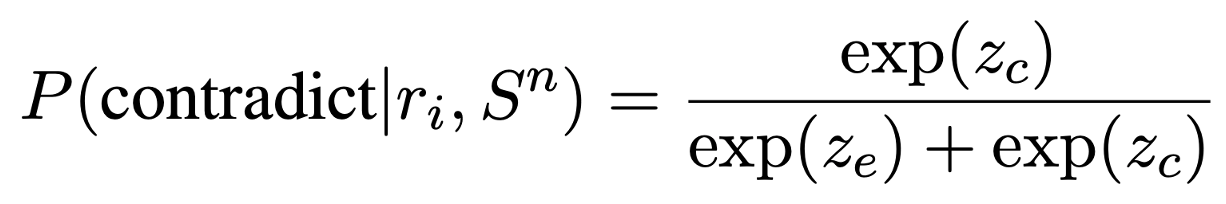
최종 NLI 점수는 다음과 같다.
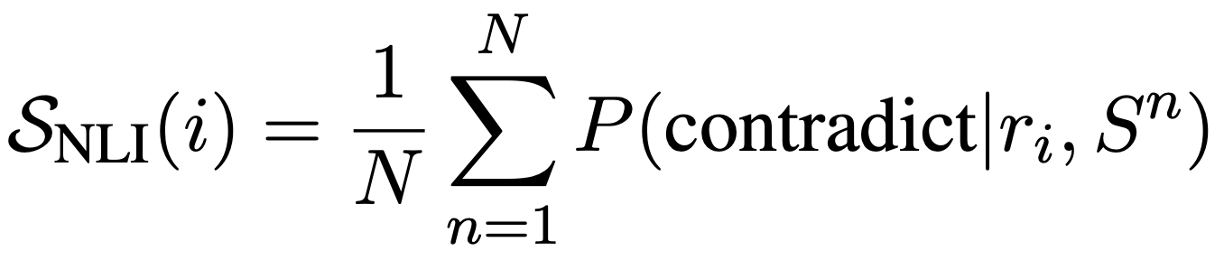
w/ Prompt
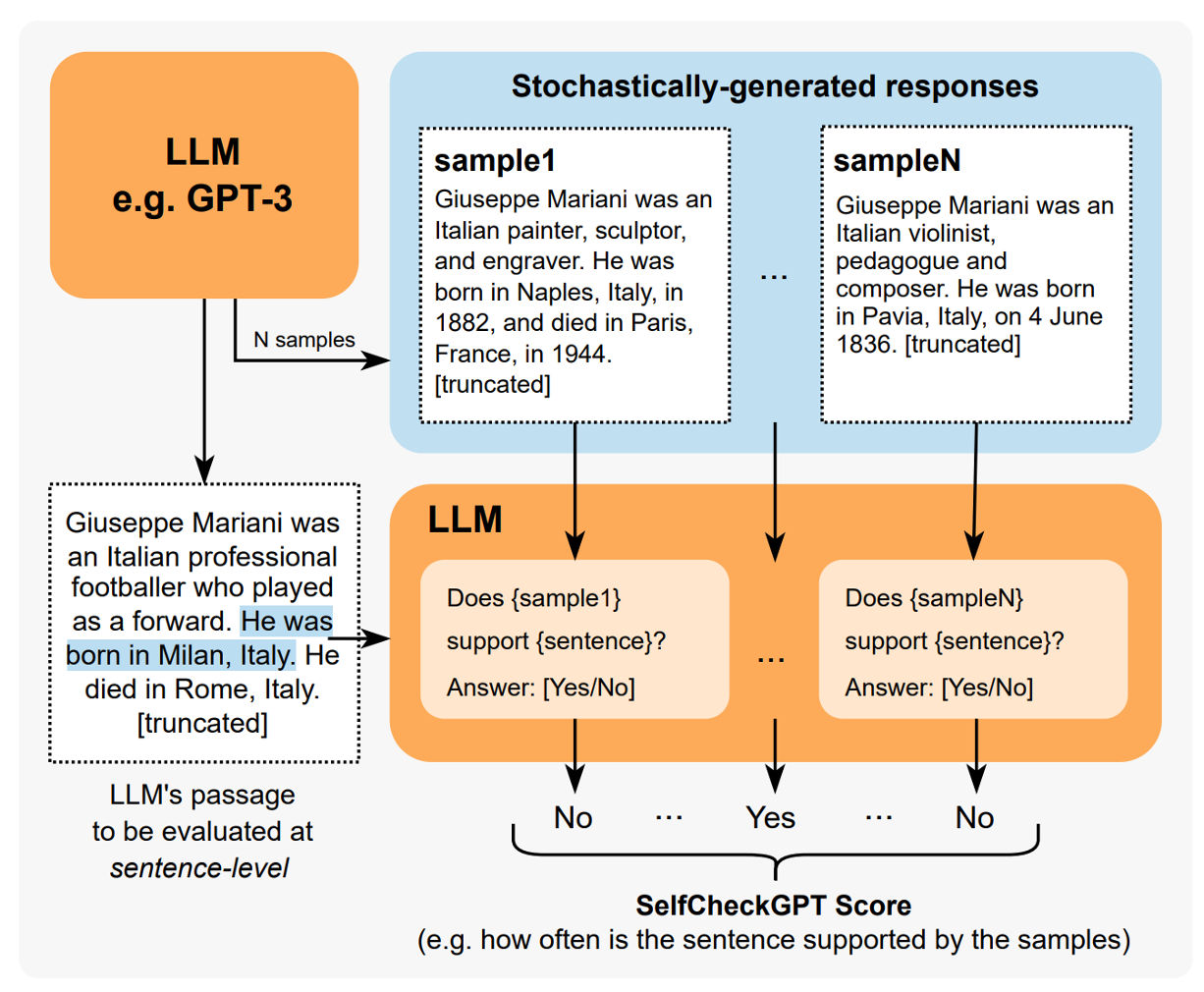
최근 zero-shot 환경에서 LLM이 consistency를 효과적으로 평가하는 것으로 나타났다. 아래와 같은 프롬프트를 사용했을 때, 98%의 확률로 yes 혹은 no를 출력하였으며, 그 외의 출력은 N/A로 평가했다.

{$Yes: 0.0$, $No:1.0$, $N/A:0.5$}로 매핑하였을 때, 최종 inconsistency 점수는 다음과 같이 계산한다.
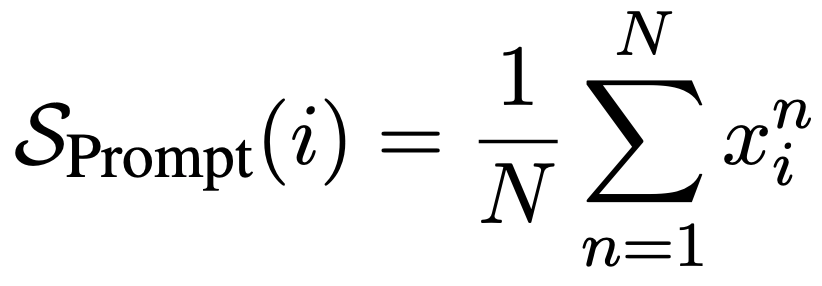
GPT-3((text-curie-001)나 LLaMA3와 같이 성능이 떨어지는 모델에서는 잘 동작하지 않는다.
Data and Annotation
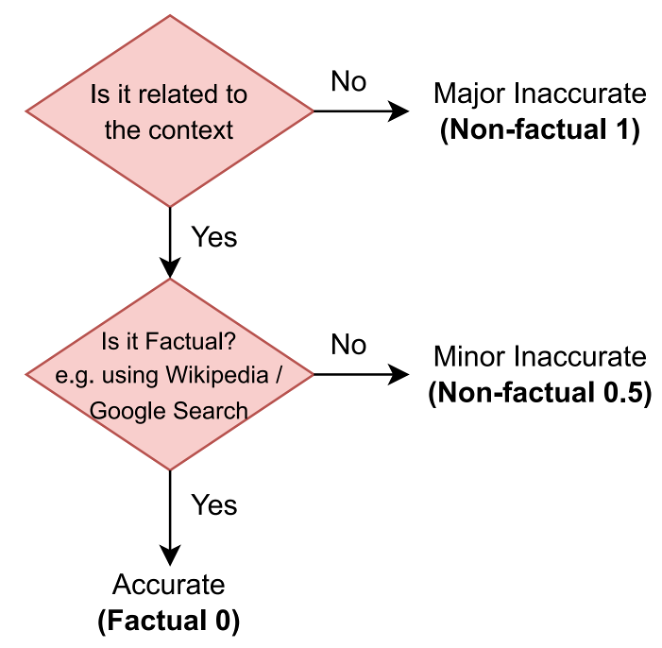
Hallucination 탐지를 위한 데이터 셋이 없기 때문에, 데이터 셋을 제안한다. 먼저, Wikipedia 문서로 이루어진 WikiBio에서 GPT-3를 통해 synthetic 데이터를 생성한다. 그 후에 생성된 문서의 문장 별로 factuality를 annotate한다. WikiBio는 Wikipedia의 특정 개념의 첫 문단을 입력으로 사용한다. “This is a Wikipedia passage about {concept}” 프롬프트를 통해 데이터 셋을 생성하며, 다음과 같이 레이블링 하였다:
Major Inaccurate (Non-Factual, 1) - 문장이 완전히 hallucinated 됨
Minor Inaccurate (Non-Factual, 0.5) - 문장이 사실이 아닌 정보를 포함하고 있음
Accurate (Factual, 0) - 문장의 정보가 정확함

생성한 데이터의 정보는 위와 같으며 1908개의 문장 중 761 (39.9%)를 major-inaccurate으로, 631 (33.1%)는 minor-inaccurate으로, 516 (27.0%)는 accurate으로 레이블링 되었다. 두 명의 평가자가 레이블링을 하였으며 불일치가 있을 경우 더 안 좋은 경우로 레이블링하였다.
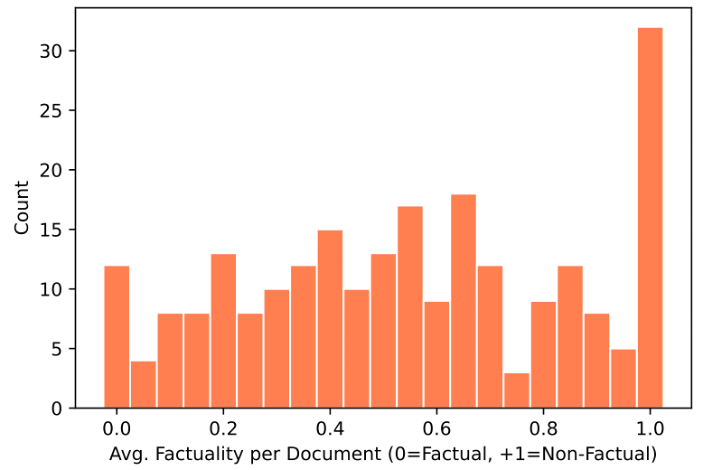
추가적으로 sentence-level을 평균하여 passage-level 점수를 평가하였다. 1.0으로 평가된 문서의 경우 total hallucination으로 보고, 해당 경우는 concept과 관련이 없는 경우이다.
Experiments
Response는 temperature을 0.0로 사용하였고, stochastic sampling의 경우 1.0으로 설정하였다. Sampling 개수 $N$=20으로 하였고 proxy LLM 접근법에는 LLaMA를 사용한다.
Sentence-level Hallucination Detection
Major-inaccurate과 minor-inaccurate 모두 non-factual 클래스로 분류하고 accurate은 factual 클래스로 분류한다. 추가적으로 문단이 total hallucination은 아니지만 major-inaccurate 문장을 포함하고 있는 경우 non-factual* 클래스로 분류하였다.
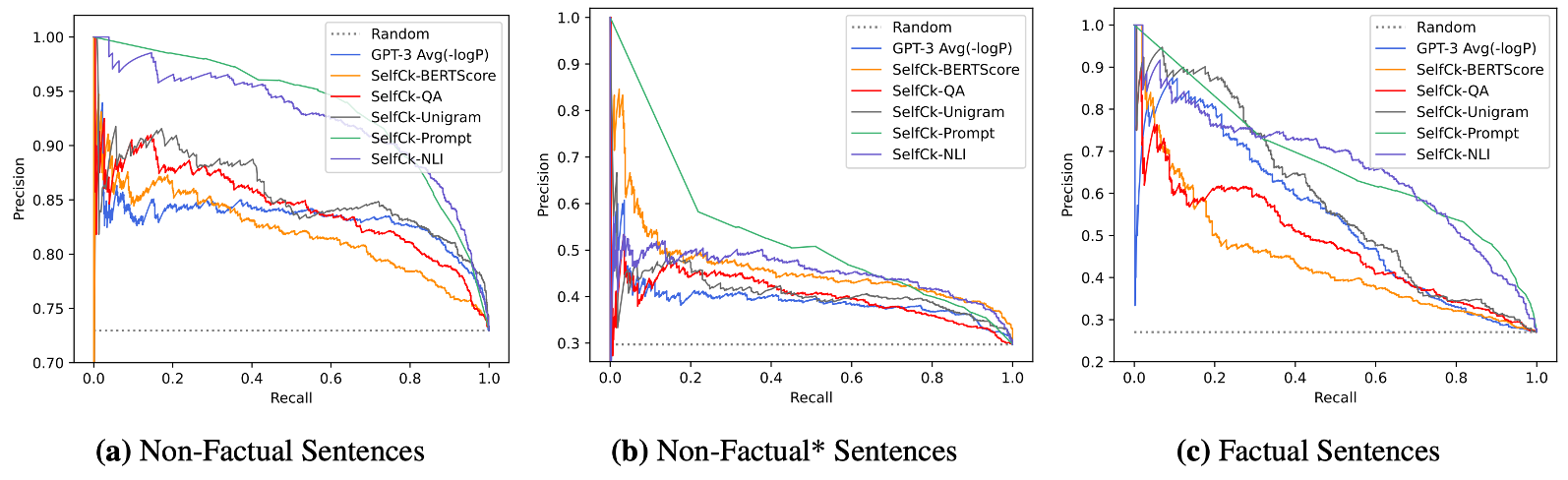
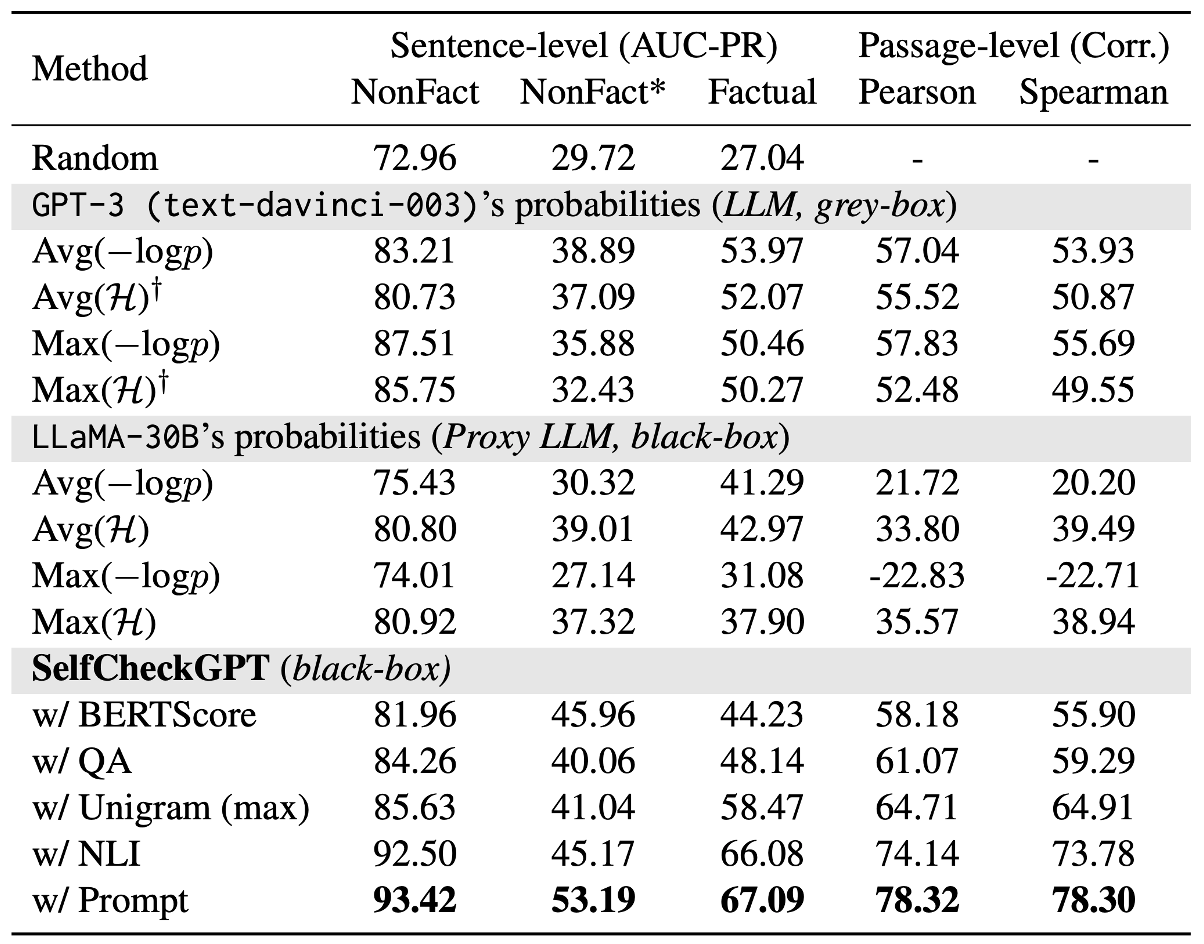
Factual 문장은 AUC-PR로 평가하였다. 랜덤 베이스라인에 비해서 LLM의 토큰 확률 이용했을 때, factual 문장의 경우 27.04에서 53.97로 향상했고, hallucination detection의 경우 72.96에서 83.21로 향상했다. 이를 통해, LLM이 생성한 정보에 대해 확신이 없을 경우, 생성한 토큰의 uncertainty가 높다는 가설을 뒷받침하며, 이는 hallucination 탐지에 방향을 제시한다. 엔트로피를 계산할 때는 top-5 토큰의 확률을 사용한다.
Proxy LLM의 경우 LLaMA를 사용했을 때, 토큰 확률을 이용했을 때보다 엔트로피를 이용했을 때 더 좋은 성느을 보인다. 이는 풍부한 불확실성 정보를 사용하는 것이 factuality 혹은 hallucination 탐지에 도움을 준다는 것을 의미하며, 이전 top-5 토큰의 엔트로피만으로는 충분하지 않았을 가능성이 있다고 암시한다. GPT-NeoX 혹은 OPT-30B을 proxy LLM으로 사용했을 때에는 랜덤 베이스라인과 유사하게 평가되었는데, 이러한 좋지 않은 성능은 LLM이 다른 생성 패턴을 가지기 때문이라고 유추한다. 추후에 weighed conditional LM가를 하는 BARTScore를 사용하는 것도 좋은 방법이다.
Black-box인 SelfCheckGPT을 사용했을 때, grey-box인 다른 방법들보다 높은 성능을 보이며 특히 SelfCheckGPT+prompt가 가장 뛰어난 성능을 보인다.. NLI를 사용했을 때, prompt 방법론에 준하는 성능을 보인다. Prompt 방법론이 계산적으로 무거울 수 있기에, NLI를 활용하는 것이 실용적인 면에서 좋아보인다.
이전의 결과들을 통해 SelfCheckGPT가 sentence-level factuality를 효과적으로 평가하는 것을 보였기에 추가적으로 passage-level factuality를 평가할 수 있는 지 분석하였다. Passage-level factuality는 sentence-level 점수를 평균으로 계산하였다.
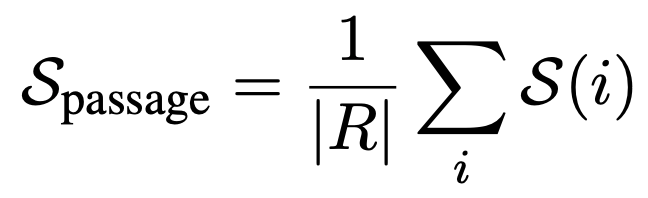
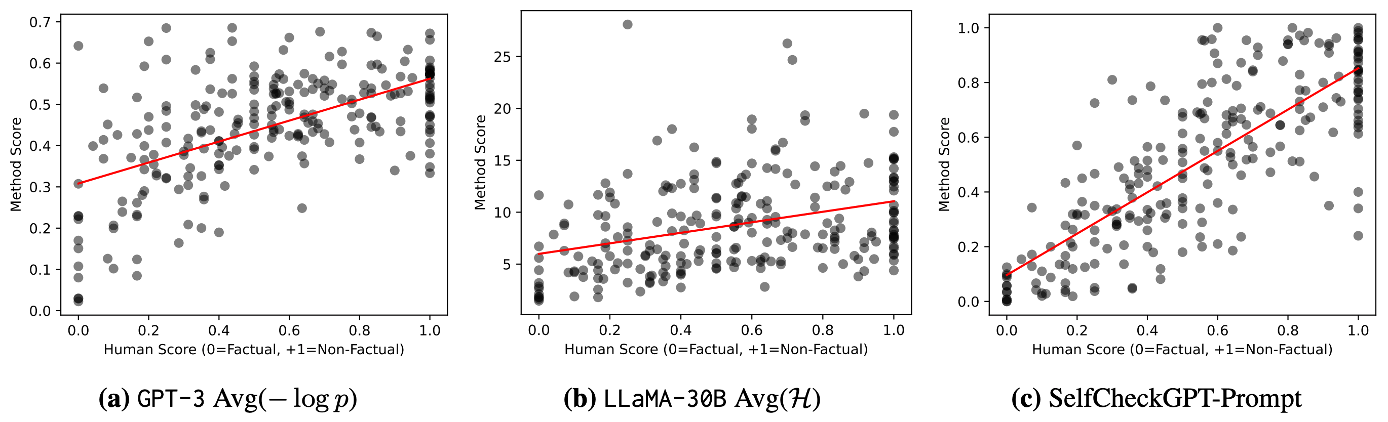
Passage-level에서도 SelfCheckGPT가 다른 방법론들에 비해 월등한 성능을 보인다. Proxy-LLM의 경우 passage-level에서 굉장히 안좋은 성능을 보인다.
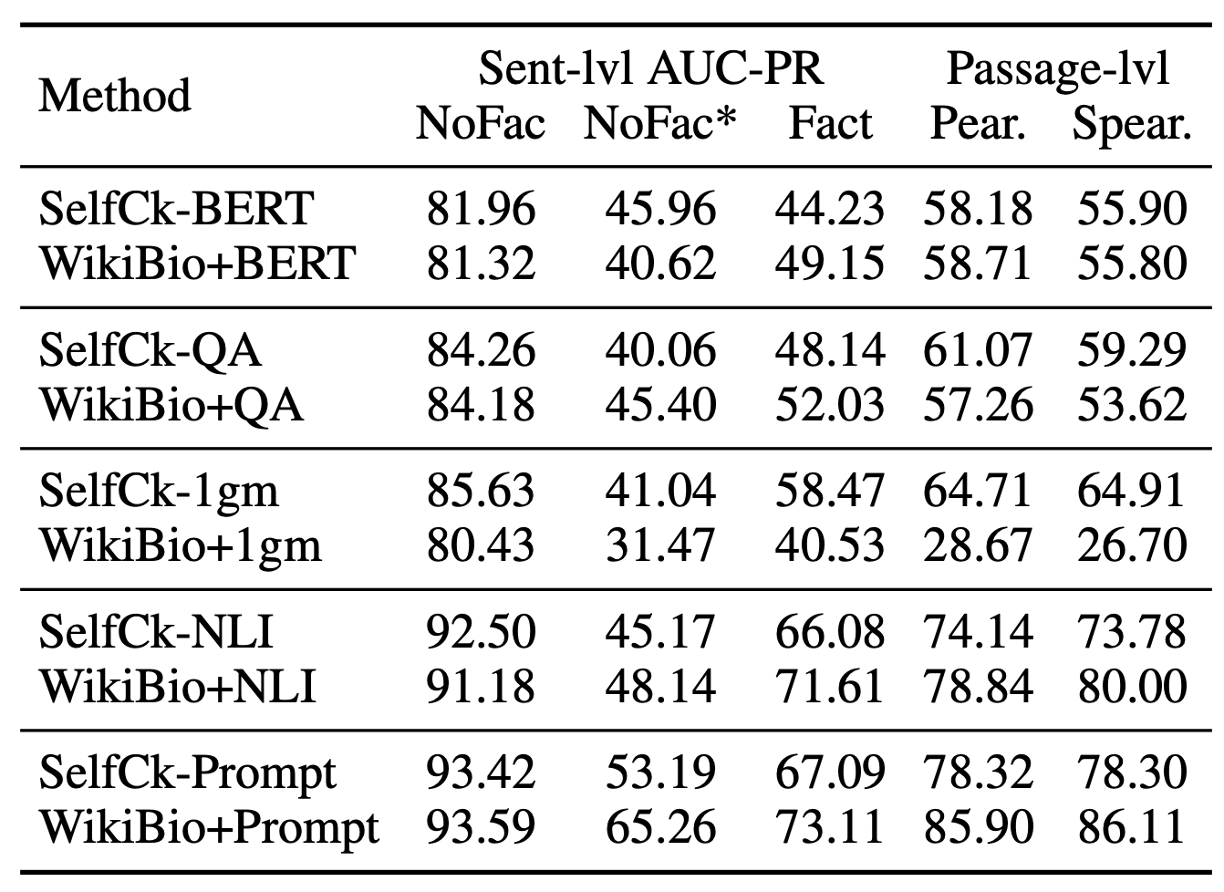
추가적인 ablation study로 sampling 대신 external knowledge가 있을 때와 비교한다. 위의 테이블을 보면 SelfCheckGPT와 reference passage를 사용하는 것이 거의 비슷한 것을 볼 수 있다. 흥미롭게도, 1-gram에서 reference passage를 사용할 때 성능이 떨어지는데 이것은 reference passage만으로 n-gram 모델을 학습하기 충분하지 않다고 판단된다. 실제 환경에서는 external database를 얻는 것이 어렵기 때문에 SelfCheckGPT가 실용적이면서도 뛰어난 성능을 보이기에 의미가 크다.
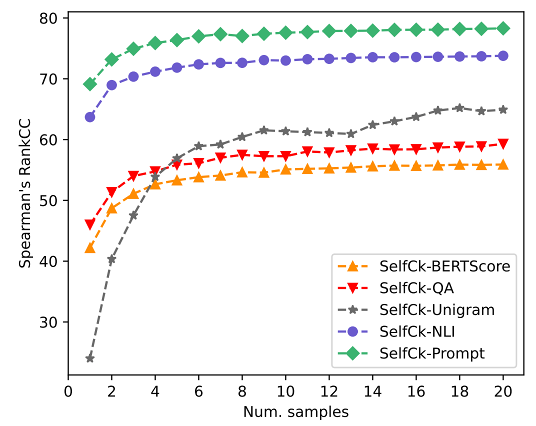
Sampling 기반 방법론들은 더 많은 생성이 있을 때 더 좋은 성능을 보일 것이라 기대하지만 computational cost가 크다. 따라서, sample의 개수에 따라 성능 변화를 측정하였는데, 위의 figure에 보이듯이 더 많은 sample이 사용될수록 점진적으로 성능이 증가했다. N-gram 모델이 가장 많은 sample을 사용할 때 성능 향상 폭이 줄어들었다.
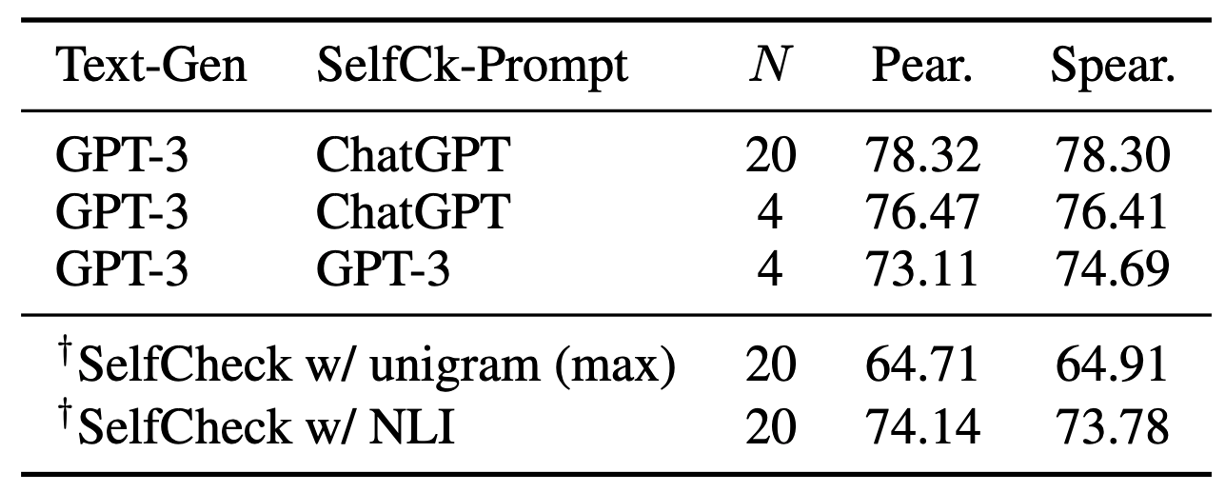
GPT-3가 자기자신이 생성한 글들도 평가할 수 있는 지에 대해 평가하였다. 실험은 N=4으로 작게 진행되었으며, GPT-3로 평가했을 때도 다른 모델들에 비해 훨씬 뛰어난 성능을 보였으며 거의 ChatGPT에 비등한 성능을 보인다.
Limitation
WikiBio의 concept에 대해서만 텍스트가 구성이 되어있는데 실질적인 LLM의 hallucination을 평가하기 위해서는 범위를 넓힐 필요가 있다. 또한 한 문장이 factual과 non-factual 정보들을 동시에 포함하고 있을 수 있기 때문에 하나의 문장을 atomic 단위로 쪼개는 것도 고려되어야 한다. 마지막으로 sampling이 computational cost가 높기에 future work에서는 efficiency를 고려해야 한다.
Conclusion
해당 논문은 LLM의 사전 지식만을 활용하여 LLM의 hallucination을 평가하는 방법론을 제시한다. Sampling을 통해 생성된 텍스트들과 다양하게 비교하는 것이 흥미로웠다. 다만, factuality와 uncertainty가 동일 선상에 있는 지에 대한 분석이 부족하다. 만약 LLM이 온라인에 퍼진 잘못된 정보를 학습하였다면 확신을 갖고 잘못된 정보를 생성할 수도 있기에 다양한 분석이 필요하다고 생각한다. 또한 계속 업데이트 되는 정보 (e.g. 현재 미국의 대통령)의 경우 LLM이 언제 학습이 되었느냐에 따라 결과가 바뀔 수 있다.